# 仓颉基础编程及应用
# 仓颉编程语言入门
# 一、基本概念
仓颉编程语言制定了一些命名规则,符合规则的名字被称为标识符
# 普通标识符:
- 由英文字母开头,后接零至多个英文字母(cangjie)、数字(cangjie2025)或下划线(cangjie_2025_11)
- 由一至多个下划线开头,后接一个英文字母(_c),最后可接零至多个英文字母(_cangjie)、数字(_919)或下划线(o_o)
- 原始标识符是在普通表示符或关键字的外面加上一对反引号,主要用于将关键字作为标识符的场景
# 变量
变量将一个名字和一个特定类型的值关联起来
变量分为可变变量、不可变量和常量
可变变量:
可变变量在定义后,还可以被赋予其他值
var name: type = expr
| 函数 | 意义 |
|---|---|
| var name | 变量名 |
| type | 变量类型 |
| expr | 初始值 |
不可变量:
不可变量在定义后,它的值不能再改变
let name: type = expr
常量:
常量在被定义后,它的值也不能被改变
const name: type = expr_const(下划线后面是下标)
常量和不可变量的区别:
常量的初始值在编译时确定,而不可变量的初始值在运行时确定
当初始值具有明确类型时,可以省略变量类型标注,编译器会自动推断出变量类型
案例:
我们使用统计方法估算圆周率的值,就是向一个正方形中随机投点,统计落入正方形内接圆的点数,落入圆的概率是 PI/4
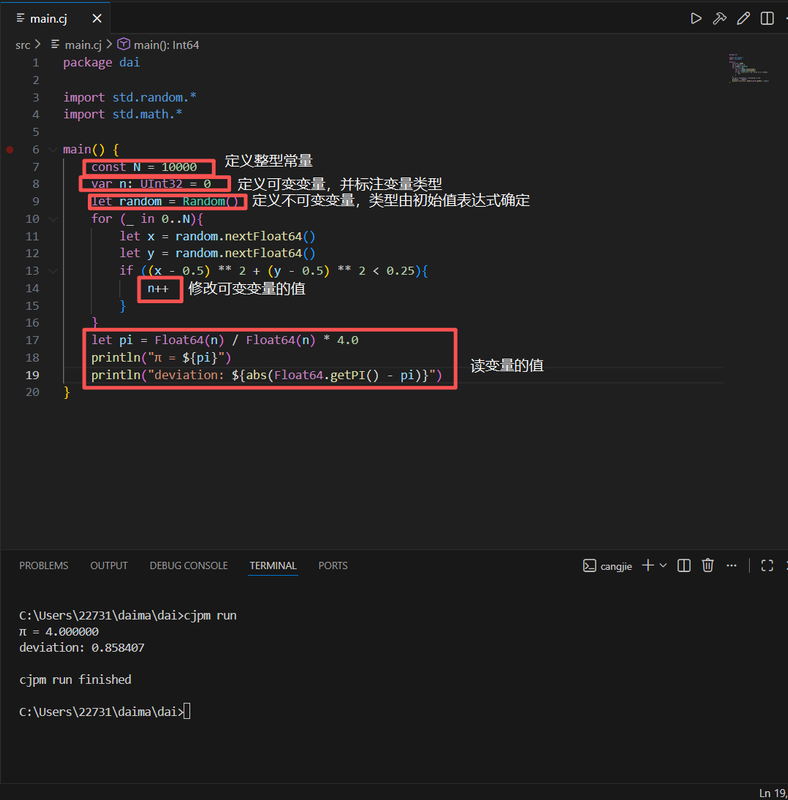
仓颉标准库提供的 random 包:它用于产生随机数
# 数据类型
规定了一块数据的组织结构即相应的解析和操作方式
let a: Int64 = 2024(64 位有符号整数类型)
let b: 67u8(8 位无符号整数类型,u8 后缀指示了这个字面量的类型,所以可以省略变量类型标注)
整数类型名及对应的字面量后缀
| 整数类型 | Int8 | Int16 | Int32 | Int64 | UInt8 | UInt16 | UInt32 | UInt64 |
|---|---|---|---|---|---|---|---|---|
| 字面量后缀 | i8 | i16 | i32 | i64 | u8 | u16 | u32 | u64 |
let c: Float64 = 6.21(64 位浮点数类型)
浮点数类型名及对应的字面量后缀
| 浮点数类型 | Float16 | Float32 | Float64 |
|---|---|---|---|
| 字面量后缀 | f16 | f32 | f64 |
let d: Bool = ture || false(布尔类型,表示逻辑运算中的真与假,因此它只有两个取值,对应字面量是 ture 和 false, 等号右侧用逻辑 “或” 运算符连接了这两个字面量)
let e: Rune = ' 仓 '(字符类型,可以表示所有 Unicode 字符)
字符类型的字面量由一个 Unicode 字符,外加一个单引号构成
let f: Rune = '\u {9889}'(字符类型的另一种字面量写法,以 Unicode 值定义字符)
这里的 9889 就是仓颉的 “颉” 字对应的 Unicode 值
let g: String = "Cang" + "jie"(字符串类型,它的字面量是在一对双引号之间写零到多个 Unicode 字符)
但不能换行,所以这也被称为单行字符串字面量,字符串之间可以用 + 操作符执行拼接操作
let h: String = " " "
若到江南赶上春,
千万和春往。
“ ” “
给出了多行字符串字面量的写法
let i: String = "Cangjie${a}"(插值字符串的写法,在以上字符串字面量中,支持写一到多个插值表达式)
要求表达式的类型实现了 ToString 接口
let j: Array<UInt8> = [67u8, 97u8, 110u8, 103u8](数组类型,UInt8 是数组类型的参数,表示数组的元素是 UInt8 类型,数组字面量就是在一对方括号之间写一组由逗号分隔的数组元素字面量)
Array 是引用类型
let k: VArray<Rune, $2> = ['C', 'J'](VArray 类型,是值类型的数据)
声明 VArray 类型时,除了要给出数组元素的类型,还要指定数组元素的个数
let l: (Int64, Float64) = (2024, 6.21)(元组类型,是一种组合类型,可以将多个不同类型的值组合在一起)
let m: Range<Int64> = 2019..2024(区间类型,表示一个有固定步长的取值范围,主要用于 for-in 表达式中)
# 表达式
在程序中,取值并不仅仅来源于字面量,我们可以用 “表达式” 这个概念来描述所有可以求值的程序元素
仓颉语言不仅有传统的算数运算表达式,还有条件表达式、try 表达式、match 表达式、flow 表达式等,它们都可以被求值
let result = (x ** 2 + y ** 2) ** 0.5
let result = if (x > 2024) {block} else {block}
let result = try {block} catch (e: Exception) {block}
let result = match (color){
case Red(value) => block
case Green(value) => block
case _ => block
}
let result = data |> fn1 |> fn2 |>fn3
......
示例中的 block 表示代码块,它代表一个顺序执行流,其中的表达式将按编码顺序依次执行
block := (expr(表达示)| decl_var(变量声明,其中var是下标))*
在以上求值场景中,if/try/match 等表达式的值等于执行代码块中最后一个表达式的值。如果代码块是空的,则规定其类型为 Unit,Unit 类型唯一取值的字面量是 ()
# 控制执行流的基本表达式:if 表达式、while 表达式、for-in 表达式
# if 表达式
它会根据一个布尔类型表达示的取值选择执行不同的分支
if 表达式的语法:
if(expr_Bool(Bool是下标)){
block (if分支)
} else if (expr_Bool(Bool是下标)){
block
} else { ?
block
}
else 后可接新的 if 表达式或一个代码块
如果圆括号中的 Bool 表达式取值为 ture,则会执行 if 分支;如果取值为 False,则会执行 else 分支,如果 if 表达式具有 else 代码块,则总有一个代码块会被执行,这种 if 表达式的值就等于所执行代码块中最后一个表达式的值
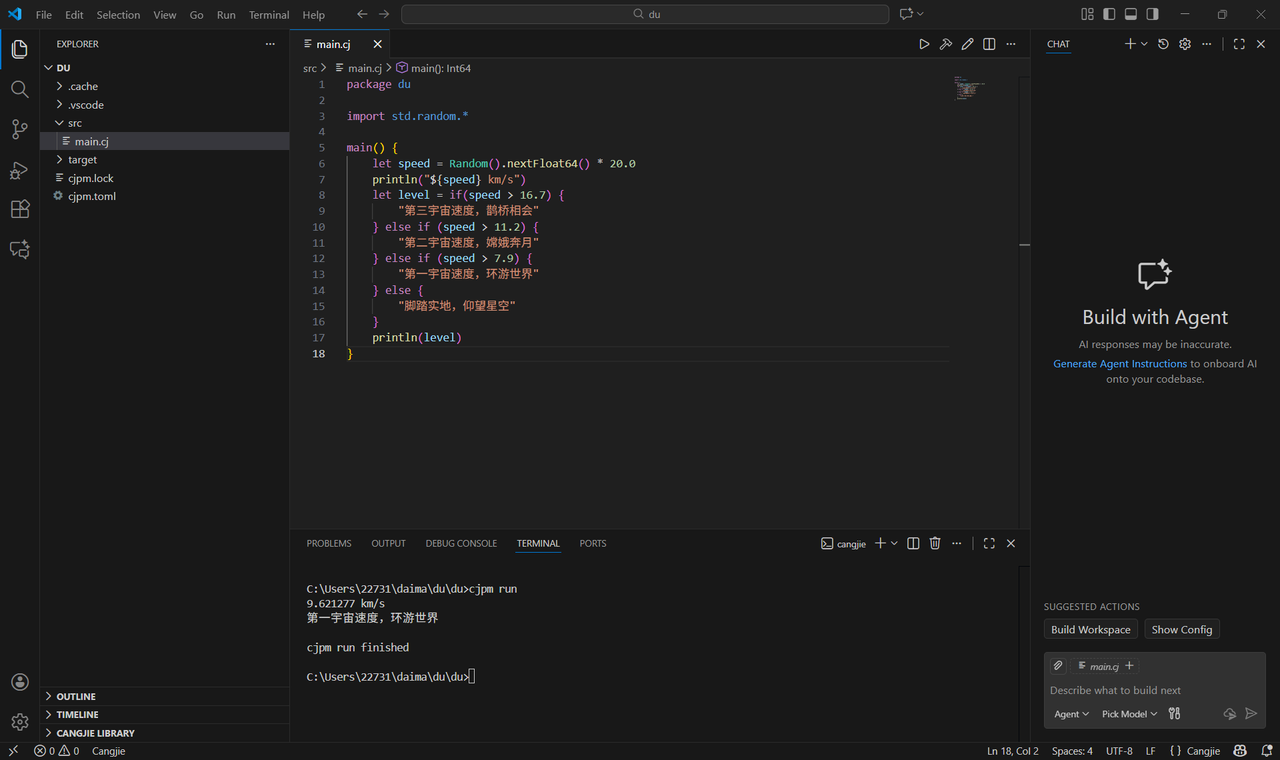
示例:
使用仓颉标准库的 random 包,产生一个浮点类型随机数 speed,表示一个飞行速度,我们使用 if 表达式判断 speed 所属的宇宙速度区间,并在各分支给出相应的描述字符串,这些字符串都是使属代码块的最后一个表达式,且总有一个代码块会被执行
因此,在对这个 if 表达式求值时,将获得所执行代码块中的字符串
# while 表达式
如何一段程序的执行流程,只会涉及三种基本结构 [顺序结构(代码块)、分支结构(if 表达式)和循环结构(while 表达式)]
while 表达式会根据一个布尔类型表达式的取值,选择是否执行循环体,如果执行了循环体,又会转回执行这个布尔表达式,由此实现一种循环执行流
由于循环体可能不被执行,所以规定 while 表达式的类型为 Unit
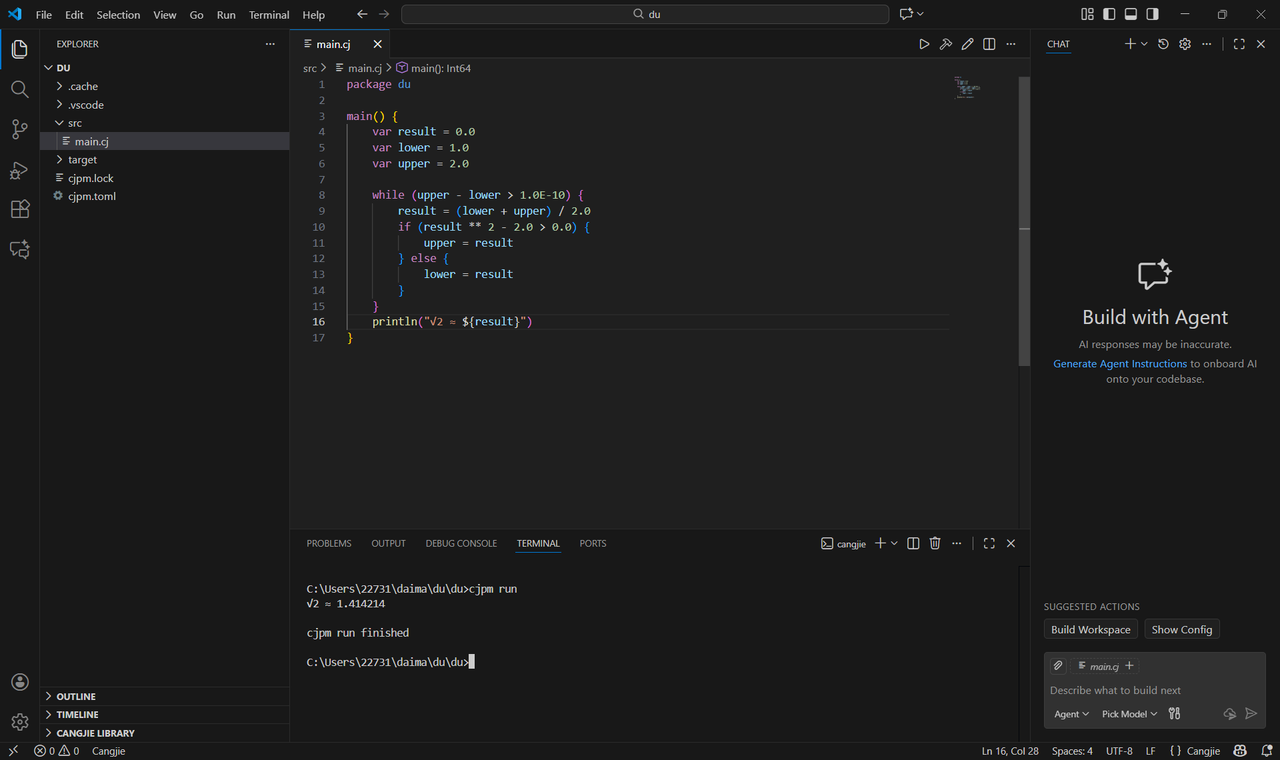
示例:
这里我们用二分法估算 2 的平方根,变量 upper 和 lower 设置了估算区间,在循环体中,我们计算这个区间的中间值,并判断这个中间值的平方和 2 和大小关系,由此更新上下界,缩小估算区间,我们需要反复执行这些操作,直到估算区间足够小,
因此,我们的循环条件就是区间长度大于某个足够小的值
# for-in 表达式
循环结构的另一种表达式
在很多背景中,我们需要遍历一个集合或区间等,对其中每个值作相同的操作
for (name(循环变量) in expr_terable(遍历对象,其中terable是下标)) {
block(循环体)
}
for-in 表达式就提供了这样的能力,它可以遍历如何一个实现了迭代器接口的类型实例
其遍历对象的类型需要实现迭代器接口 Iterable<T>,运行时,将逐次调用迭代器取值并执行循环体,在循环体中可以循环变量引用对应值
注意:循环变量是不可变的
由于循环体可能不被执行,所以规定 for-in 表达式的类型为 Unit
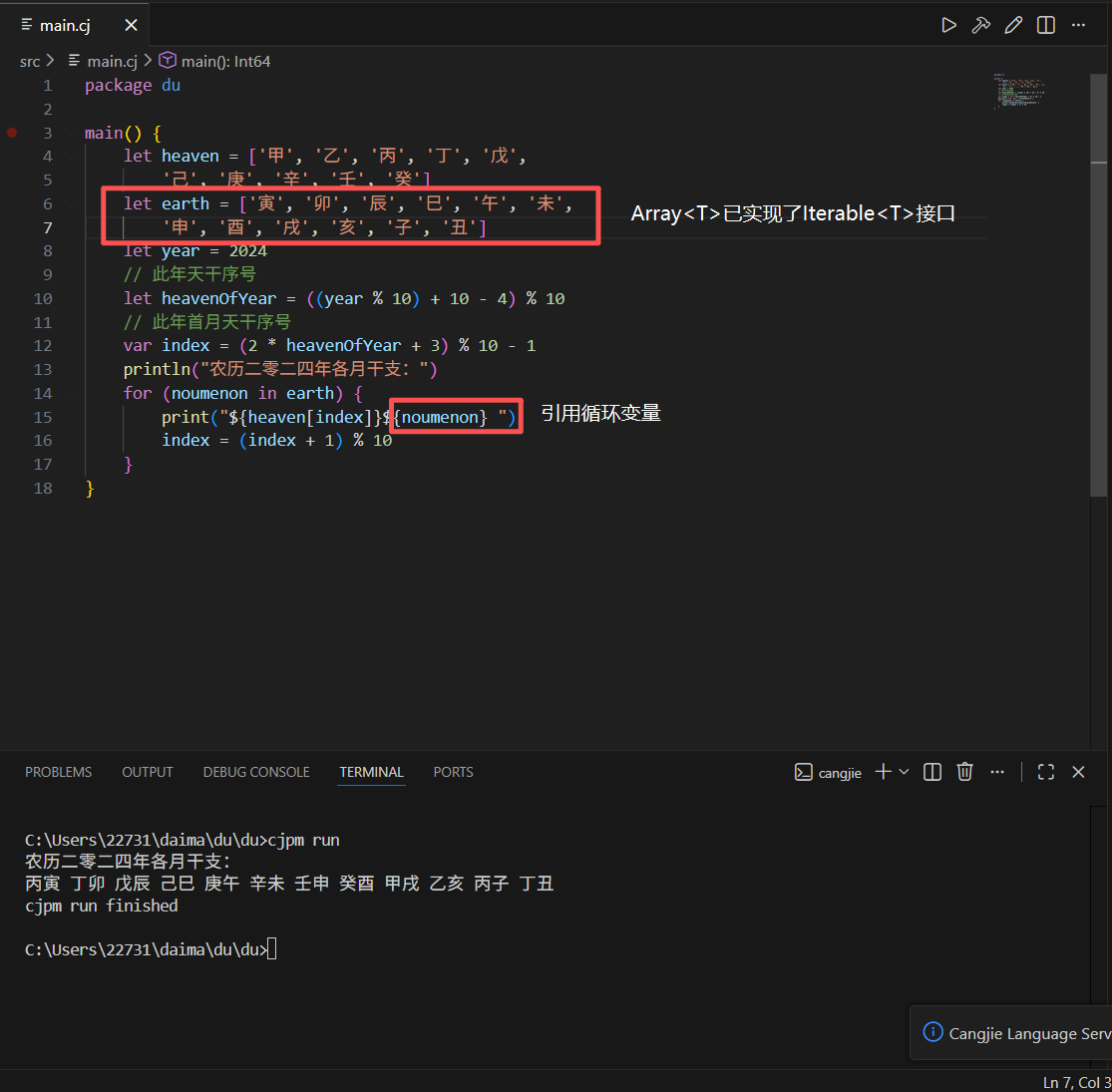
实例:
我们计算和输出 2024 年各月的干支纪发,数组 heaven 和 earth 分别存放十天干和十二地支的字符,通过相关转换算法,我们得到 2024 年首月对应的天干序号 index,而每年正月到腊月的地支的固定为寅到丑,所以我们只需要按序遍历地支数组,并从天干数组的 index 处依次取值和地址关联,天干是循环使用的,所以 index 再递增过程中做了模 10 计算
由于仓颉已经为数组等集合类型实现了迭代器接口,所以这里可以直接使用 for-in 去遍历
for-in 表达式还有其他几种用法:
-
遍历对象可以是 Rabge 表达式
var sum = 0 for (i in 1..=99:2){ sum += i * i }实例中的 Range 表达式产生一个从 1 到 99,步长为 2 的区间实例,在遍历过程中将依次取值,并且包含 1 和 99 两个边界值
-
当迭代器取值为元组类型时,可以在定义循环变量时进行解构,循环中就可以直接引用元组中的各个值
let array = [(1, 2), (3, 4), (5, 6)] for ((x, y) in array) { println("${x}, ${y}") } -
如果在循环体中无须引用循环变量,只需要重复执行多次循环体,则可以用一个下划线即通配符去替代循环变量,这样可以避免编译器告警
var number = 2 for (_ in 0..5) { number *= number } -
可以在遍历对象后,用 where 引导一个布尔表达式,当它取值为 ture 时才会执行循环体
这个布尔表达式一般会引用循环变量,作为迭代元素的过滤器
for (i in 0..10 where i % 2 == 1) { println(i) }
# 程序结构
** 包:** 是仓颉程序的最小编译单元,一个包由一到多个源文件组成,在每个文件可以声明当前文件所属包(如果没有文件声明,则默认属于名为 default 的包),也可以导入其他包,由此实现程序的高效管理和复用
在一个包中,也可以通过导入声明来引用其他包,而同一个包中的各个源文件之间总是共享程序元素的
在包的顶级作用域中,可以定义一系列的变量、函数和自定义类型(枚举、结构体、类、接口),以及包的声明与导入等,其中的变量和函数被称为全局变量和全局函数
在非顶层作用域中可以定义变量和函数,称为局部变量和局部函数。自定义类型中的局部变量和函数,称为成员变量和成员函数
如果要将包编译为可执行文件,需要在顶层作用域中定义一个 main 函数作为程序入口
程序启动时将从 main 开始执行,main 函数可以没有参数,也可以声明一个 String 数组类型的参数,程序启动参数将通过这个数组传递给 mian 函数
main 函数的返回值类型可以是整数类型或 Unit 类型
# 二、函数修改
# 定义函数
函数是一个参数化的代码块,在调用函数时,这个代码块实现特定功能并可以被求值,结合函数参数实现特定范围的代码复用
** 函数定义的要素:** 函数名、参数列表、返回值和函数体
func name(params): type {
block_func(func是下标)
}
# 参数列表
参数列表是由零到多个参数声明组成的,参数分为普通参数和命名参数两种,它们有不同的声明方式
params_normal(normal是下标):= name : type, name : type*
params_name (name是下标):= name !: type, name !: type*
在参数列表中,命名参数只能在普通参数之后进行声明
params := params_normal?params_name?
可以将命名参数设置为默认值,在调用函数时,对这类函数可以省略传参,对应实参将取其默认值
name !: type = expr_const(const是下标)
# 函数体
函数体可以有零到多个表达式,变量声明或函数声明,函数参数将作为不可变变量在函数体中使用
block_func(func是下标) := (expr | decl_var(var是下标) | decl_func(func是下标))*
在函数体中定义的函数被称为嵌套函数,嵌套函数可以捕获其外层作用域中的局部变量,由此构成闭包
在函数体中可以用 return 表达式返回一个值,执行 return 后会跳出当前函数,返回到调用处继续执行
在函数体中返回值
return expr
函数类型的表达方式
(type, type)* -> type 有参
() -> type 无参
在仓颉语言中,函数是一等公民,它不仅可以被调用,也可以作为一个值去传递在这种场景,我们可能需要写出对应的函数类型名
# 调用函数
我们通过函数名和实参列表来调用一个函数
实参列表由零到多个表达式构成,这些表达式的值就是对应位置的参数值
命名参数对应的实参前还要加上参数名前缀
name_func(func是下标)(args(实参列表))
args := args_normal(下标)?args_named(下标)?
args_normal := expr, expr*
args_named := name_param : expr, name_param : expr*
在实参列表中,可以省略有默认值的命名参数,这时对应实参将取其默认值
函数不仅可以被调用,还可以作为值去使用,如赋值给变量、作为函数的参数和返回值等
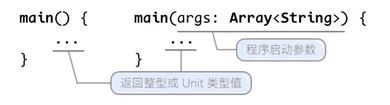
实例:
在顶层作用域中我们定于了 void 和 node 两个函数,node 函数不仅有字符类型的参数 value,还有两个函数类型的命名参数 left 和 right,并且以 void 函数作为它们的默认值,在 node 函数体中,我们又定义了一个嵌套函数 show,在 show 函数体内引用了外层函数的参数,由此构成了闭包
这个闭包会被分配专属的空间来存储 left、right 和 value 的值,最后 node 返回了 show 函数,基于闭包的特性,node 函数每次被调用时,实际上会返回不同的 show 闭包实例,每个实例可以持有不同的 left、right 和 value 值
在这个基础上,我们仅通过 node 函数调用,得到了一个具有二叉树结构的闭包
# lambda 表达式
它相当于函数类型的 “字面量”,让函数作为值去使用的开发场景更加高效灵活
lambda 表达式可以让函数的创建和使用更加灵活
lambda 表达式的值就是一个匿名函数
lambda 表达式的语法:
{params => block_func(下标)}
其中参数列表和函数体的写法和普通函数的保持一致
lambda 表达式中无需标注返回值类型,仓颉编译器会从上下文中自动推导
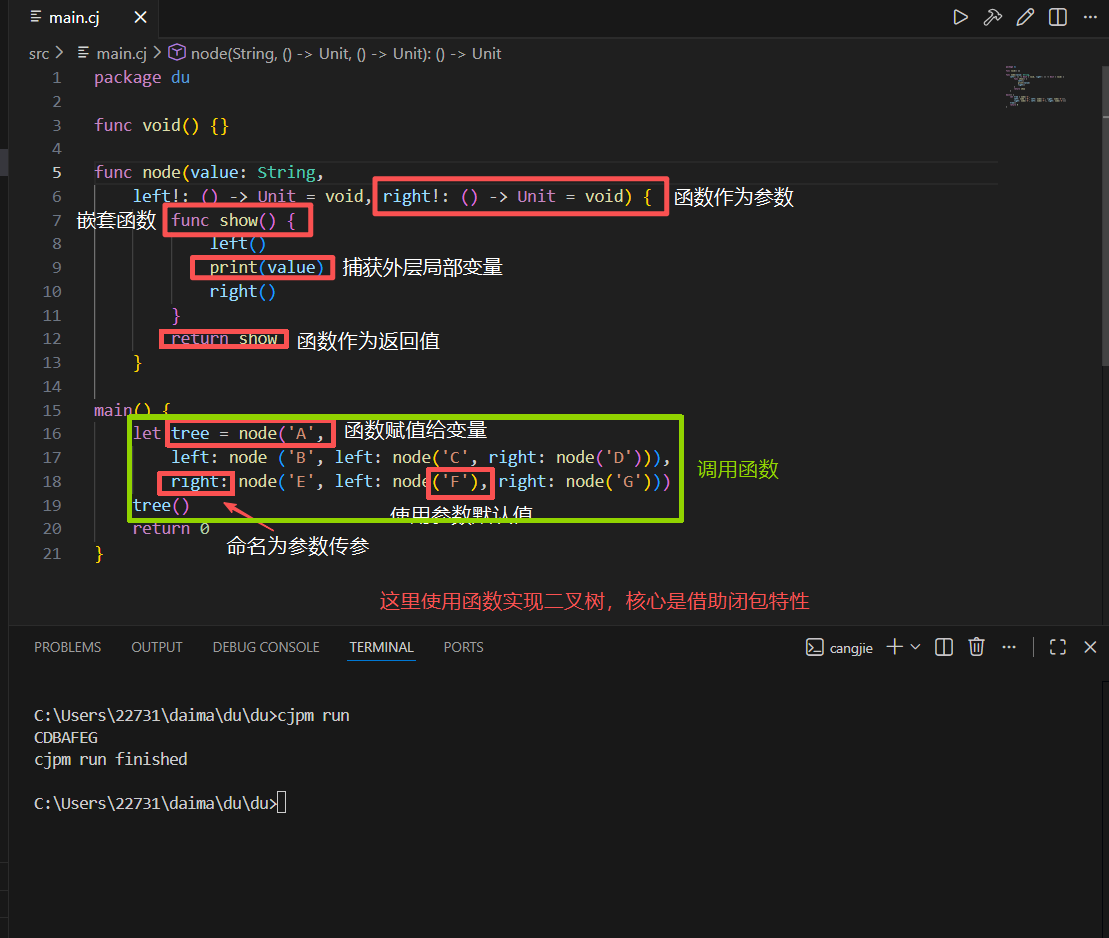
实例:
我们定义一个全局函数 iter,它具有一个函数类型参数 f,iter 函数的功能是以 x0 为初始值迭代计算一元数学函数 n 次,并打印出这个迭代序列,在调用 iter 时,我们直接在实参列表中用 lambda 表达式给出了对应的函数实参(不必像上一个函数实例中专门定义全局函数来作为函数实参),而且在多次调用 iter 时会更显简洁
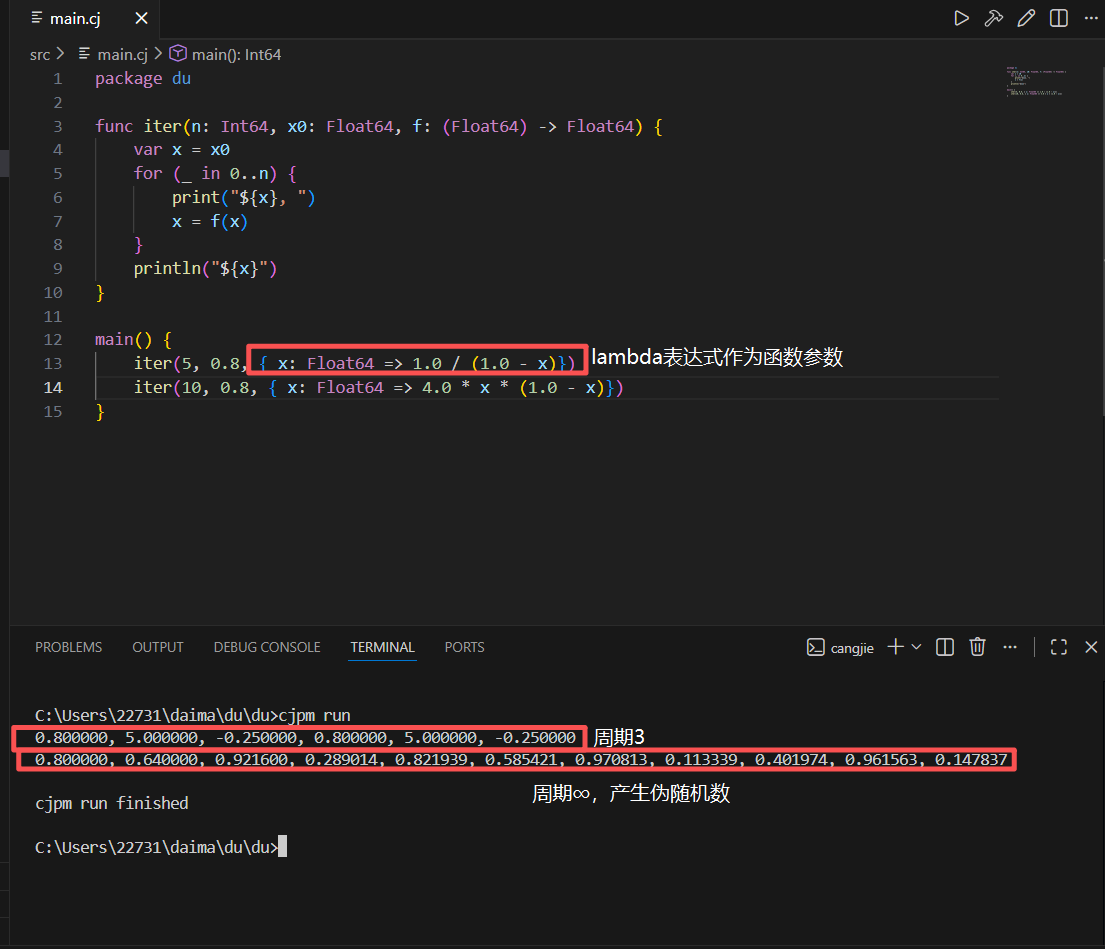
这是产生伪随机数的一种方法
# 三、枚举
# 定义与实例化
通常,我们使用枚举类型来定义一组有关联的符号,在一些场景中用来做分类和标记等等,这些符号的字面含义可以增强程序的可读性
仓颉语言的枚举类型不仅支持这种传统用法,还支持定义带参数的枚举项和成员函数等,枚举项的构造函数还支持递归引用枚举自身,基于这些特性,使用仓颉语言的枚举类型还能实现代数表达和符号计算等高级功能
定义枚举类型的语法:
它主要由枚举类型名和枚举项组成,同时还支持定义成员函数和成员属性来操作枚举项
enum name(枚举类型名) {
item (| item)* |枚举项
(decl_func(func是下标,成员函数) | decl_prop(prop是下标,成员属性))*
}
枚举项可以是一个标识符或一个表示符加类型列表组成的构造器
枚举类型的取值可以是一个无参枚举项,也可以是一个给定实参的有参枚举项
item := name | name(type, type)*
在枚举类型中,可以声明一到多个枚举项,由竖线符号分隔
下划线后面都是下标
name_item
name_item(args)
在引用这些枚举项的名字时,为了避免命名冲突,也可以加上枚举类型名前缀(由 “.” 分隔)
# 成员访问规则
在成员函数和成员属性的声明前可以添加一些修饰符,它们将影响成员的访问方式
**private:** 用于设置成员仅在枚举类型定义块中可见
**pubilc:** 设置成员在枚举定类型定义块内外均可见
如果没有使用这两个修饰符,这类成员默认在当前包可见
static:设置成员为静态成员,只能通过枚举类型名访问;默认实例成员,只能通过枚举实例访问
在函数中都能引用枚举项,在实例成员函数中可以引用其他成员,在静态成员函数中只能引用静态成员
在实例成员函数中也可以使用 this 变量,它代表当前枚举实例,this 是不可变变量
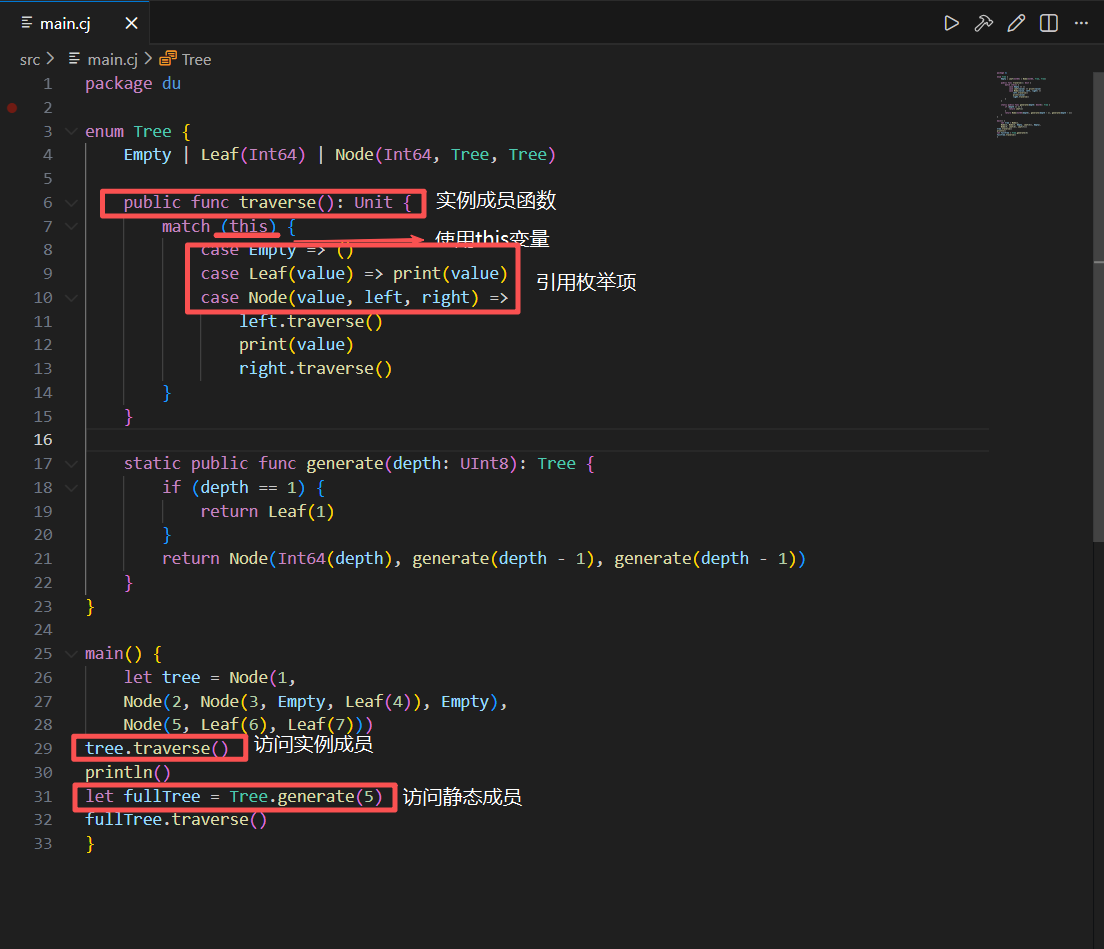
实例:
在实例中,定义了一个枚举类型 Tree,可用于组织一棵二叉树,二叉树节点是 Int64 类型,在枚举类型中定义了一个 pubilc 修饰的实例成员函数 traverse,其中引用了枚举项,this 变量和它自身,使用模式匹配解构 this 对应的枚举实例,按中序遍历打印相应的二叉树,另外定义了一个 static 修饰的静态成员函数 generate,其中引用了枚举项和它自身,用于生成一个指定深度的满二叉树实例
在 main 函数中,我们首先调用 Node 构造器手动组织了一棵二叉树,然后调用实例成员函数 traverse 按中序打印了各个节点的值,随后,我们由通过枚举类型名调用静态成员函数 generate,得到了一个 5 层的满二叉树实例,并再次调用 traverse 函数打印这棵树
# match 表达式
枚举类型能支持我们做一些有意义的符号表达和计算,而 match 表达式就是连接符号和计算的核心特性
match 表达式也称为模式匹配表达式
基本语法:
在运行时,会首先计算 match 括号中的表达式得到一个值,然后依次执行 match 块中的一到多个 case 表达式,每个 case 表达式尝试把这个值和 pattern 匹配,如果匹配成功,则执行箭头后面的代码块,然后跳出 match 表达式;如果匹配失败,则继续执行下一个 case 表达式
match(expr) {
case pattern => block
}
case 之后可以用 “或” 操作符,连接多个同类型的模式,执行这个 case 时,只要待匹配值和其中任何一个模式匹配,就算是匹配成功
可以用 “|” 连接多个同类型的模式
case pattern | pattern*
pattern 后也可以用 where 增加约束,即可以用 where 来引导一个布尔表达式
pattern 被匹配且这个布尔表达式的值为 true,才算是匹配成功
case pattern where expr_Bool(Bool是下标)
# 仓颉支持六种 pattern 的基本模式:
-
枚举模式
用于解构枚举项的构造函数
case Rot(speed) => rotate(speed) -
类型模式
case object: Plane => object.fly() -
绑定模式
case other => process(other) -
元组模式
case (name, 80) => println(name) -
常量模式
case 2024 => println("Cangjie") -
通配模式
case _ => defdault()
可以看出 match 表达式不止应用于枚举类型,但枚举类型确实是 match 表达式最常用的也是非平凡的使用场景
不同模式下,“匹配成功” 有不同的定义,在枚举模式下,表示待匹配值是由枚举项 pattern 构造的,对于有参枚举项,在 pattern 中还可以用表示符对构造参数占位,若匹配成功,待匹配值对应的参数会绑定到这些占位符上,在 case 代码块中,作为不可变变量使用,由此实现枚举项的解构
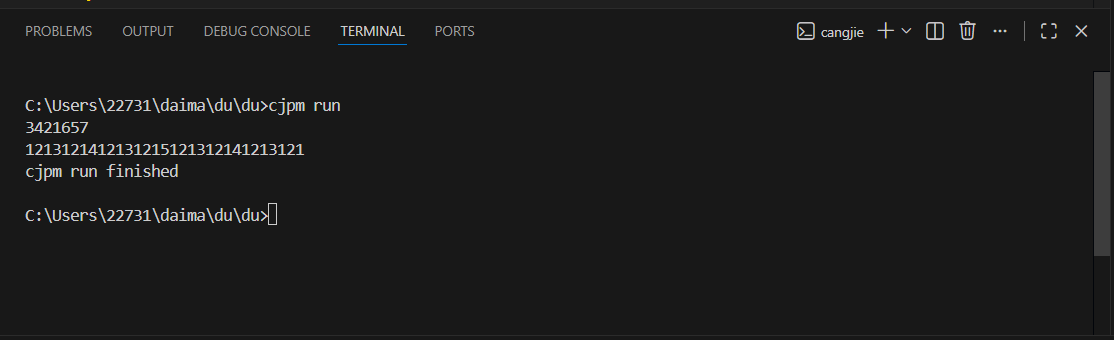
实例:
通过实例我们来简单了解其他几种模式的使用方法,这里的函数 fib 用于计算斐波拉切数的第 n 项,主要通过 match 表达式和递归调用来实现,这里 match 的待匹配值就是整数 n,第一个 case 使用常量模式,匹配边界值 0 或 1,这两项的值就是 n 本身;第二个 case 使用绑定模式和 where 约束匹配 n>1 的情况,在这个范围内,第 n 项的值等于前两项之和;第三个 case 使用通配模式,拦截 n<0 的异常情况,对这些非法输入,我们直接返回 0
# 应用实例
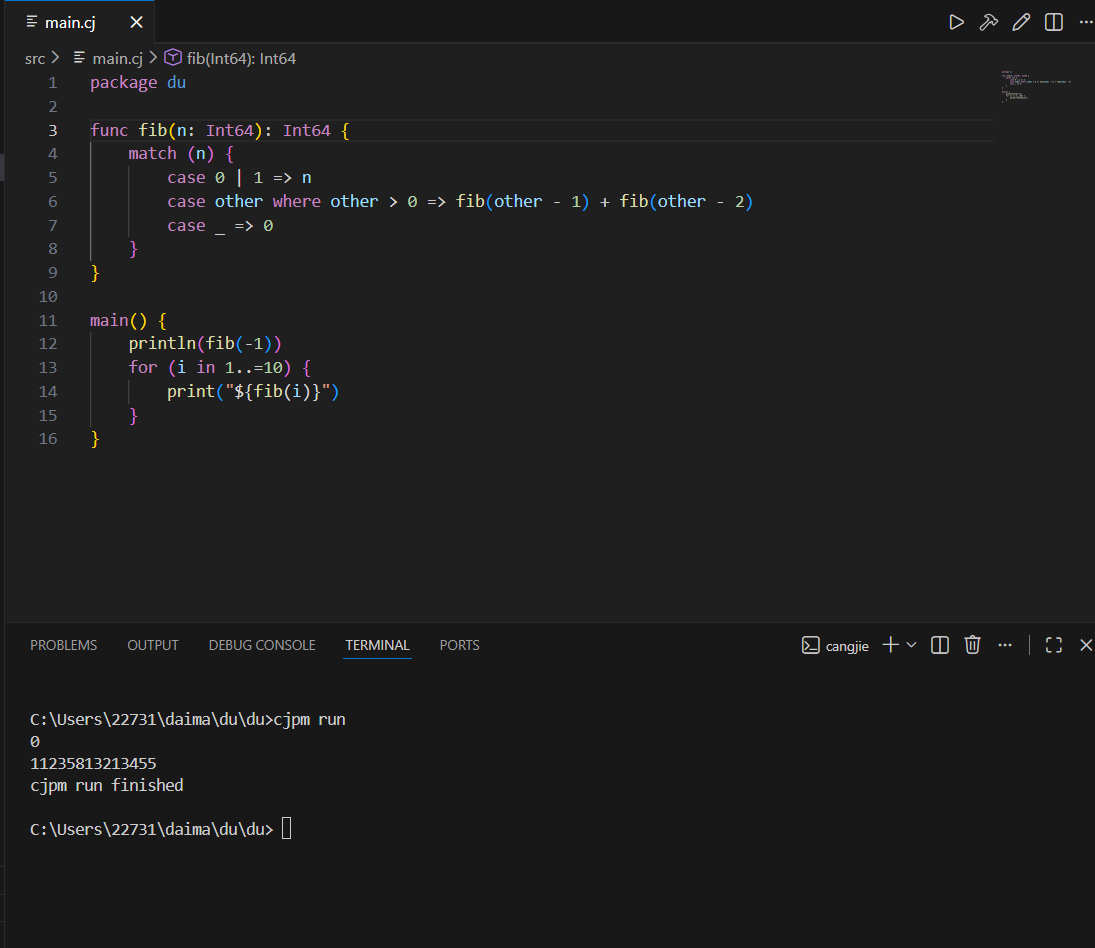
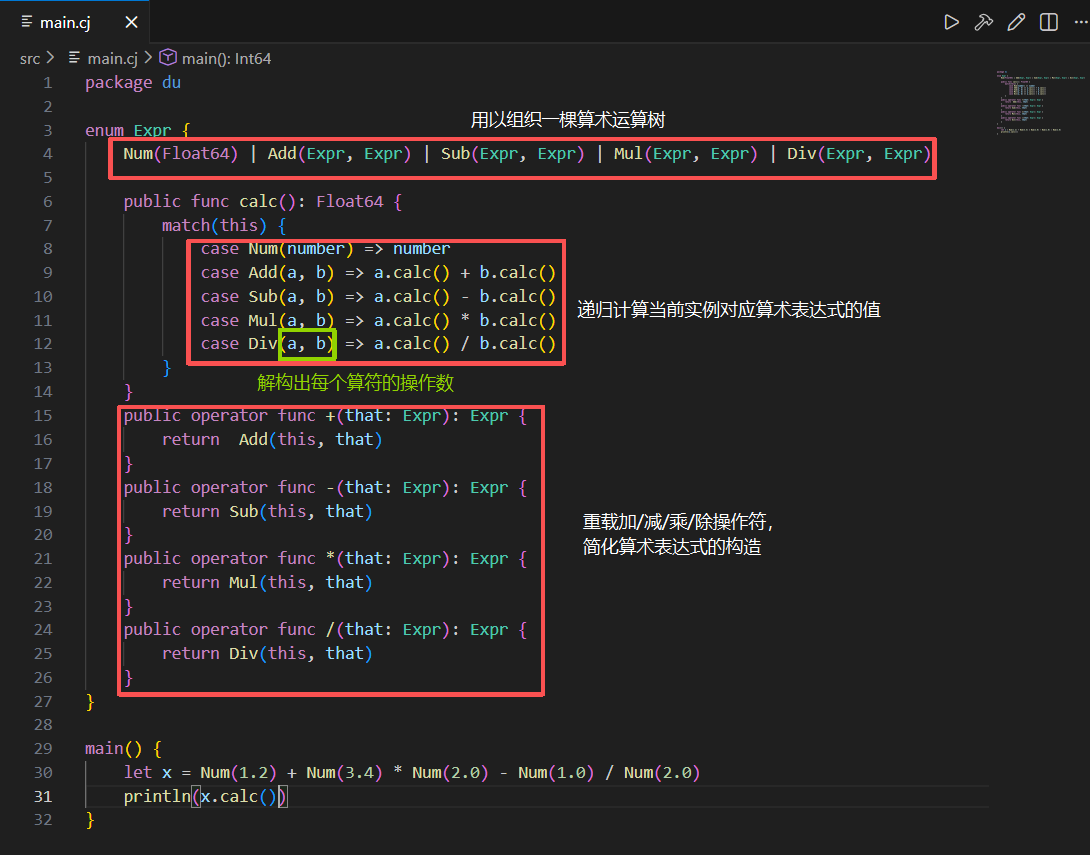
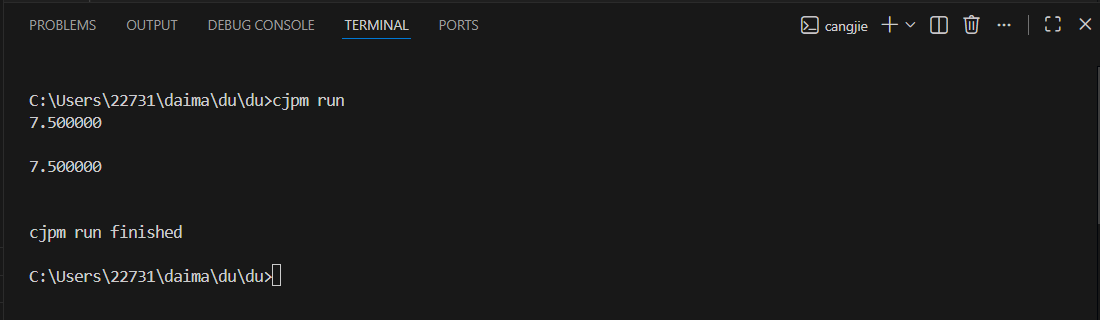
我们通过实例进一步理解枚举类型和模式匹配,这里我们用枚举类型 Expr 来描述和实现四则运算,Num 枚举项对应操作数 Add、Sub、Mul、Div 对应加减乘除 1 操作符,它们的构造参数都是两个 Expr 实例,表示它们的左右操作数,由此组织出一棵算术运算树,为了计算这棵树,我们定义了 calc 成员函数,其中使用了 match 表达式,它的待匹配值就是当前枚举实例,我们在第一个 case 中匹配和解构 Num 枚举项,如果匹配成功直接返回对应操作数,然后,我们依次匹配代表加减乘除的四个枚举项,从中解构的参数又是 Expr 类型,我们递归调用这些参数的 calc 函数进行分治求值,然后相应的操作符作汇总计算,由此实现整棵数的算数求值
最后,为便于这棵树的构造,我们还实现了加减乘除操作符函数,让使用者可以通过写一个算术表达式来构造对应的枚举实例
# Option
在有些应用场景中,一个变量不能保证在整个生命周期内都被赋予有效值,例如计算过程中出现了异常情况,或者是在一定阶段不需要被初始化等等,为了高效且安全的表达这种 “或有或无” 的值,仓颉语言提供了 Option 类型
Option 是通过枚举类型实现的,它被定义在仓颉标准库 core 包中,开发者无需显式导入即克直接引用
enum Option<T> {
None(表示无值状态) | Some(T)(表示有值状态)
public func getOrThrow(): T
public func getOrThrow(exception: () -> Exception): T (第三行和第四行:尝试获取有效值,如果失败就抛出异常)
public func getOrThrow(other: ()->T): T (尝试获取有效值,如果失败就执行指定操作)
public func isNone(): Bool
public func isSome(): Bool (第六行和第七行:判断当前实例是否持有有效值)
}
这里 T 是一个类型参数,表达有效值的类性,Option 具有两个枚举项 None 和 Some,分别表达无值和有值的状态,同时还具有几个成员函数,用于取值和判断状态
创建 Option 实例:
var result = Some(2024)
var result: Option<Int64> = 2024
var result: ?Int64 = 2024
仓颉编译器为 Option 提供了相应的自动类型推导能力和语法糖,让 Option 的创建和使用更加高效,例如,在类型 T 前加一个问号,就能快速表示 Option<T> 类型
在仓颉语言中,不存在空值或空指针的概念,可能存在无效值的场景中只能用 Option 去判断处理,避免了空值相关安全问题
实例:
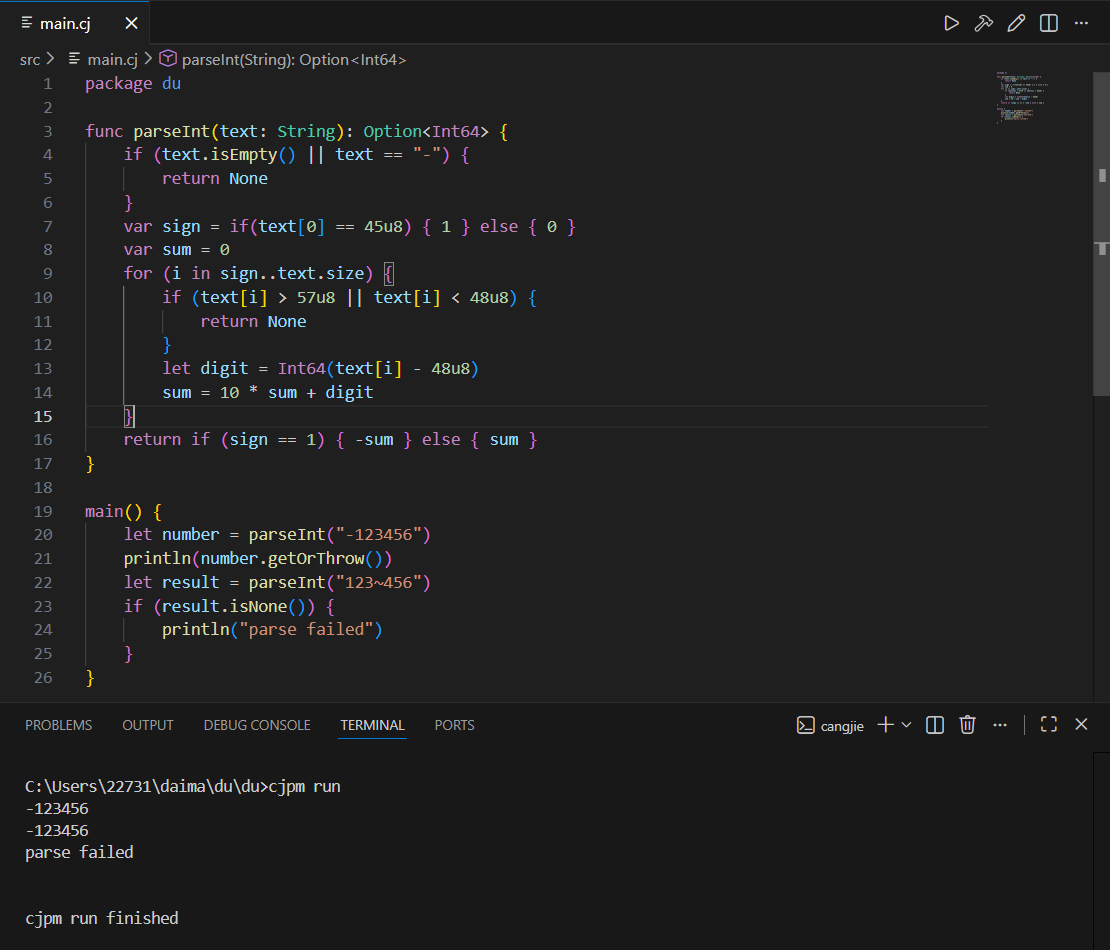
这里 parselnt 函数可以将给定的数字字符串转为对应的十进制整数,但是输入的字符串,可能不符合整数词法规则,这将导致解析失败,为此,我们定义 parselnt 函数的返回值类型为 Option<Int64>,如果解析失败,将返回 None,否则返回携带有效值的 Some 实例
这里导致可能解析失败的情况,主要是字符串为空,只有一个负号或出现非法字符,所以我们在这些位置返回了 None,在函数最后返回有效值时,并没有显示使用 Option 或 Some,当仓颉编译器会根据标注的函数返回值类型,将 return 之后的表达式自动包装为 Option 类型
在 main 函数中,我们调用 parselnt 函数,获得了 Option 类型变量,并调用 Option 的相关成员函数进行取值和判空操作,当然,我们也可以使用模式匹配表达式来解构 Option 实例,
# 四、结构体
# 定义与实例化
结构体也是一种组合类型,通过定义若干成员变量,可以把多个不同类型的值组合在一起,同时,还可以定义成员函数和成员属性来操作这些数据成员,以此实现更复杂的数据结构个封装
struct name(结构体名) {
condtructor* (构造函数)
(decl_var | decl_func | decl_prop)*
(成员变量 | 成员函数 | 成员属性)
}
在结构体中可以定义多个构造函数,它们用于创建结构体实例
构造函数有两种:
-
普通构造函数
init(params) { block_func }除了没有 func 前缀和不可变的函数名,在定义时和普通函数基本一样
-
主构造函数
name_struct(decl_vars) { block_func }它的函数名和结构体名一致,更特殊之处是它的参数列表,其中可以直接定义成员变量,而且不必在函数体中再为这些变量赋值,调用时传入的实参会自动赋给相应的成员变量
decl_vars 是对成员变量的声明,在此统一了成员变量的定义和初始化,减少冗余编码
在结构体中可以定义多个普通构造函数,当最多只能构造一个主构造函数
创建结构实例:
name_struct(args)
调用任何一个构造函数,都将返回一个结构体实例,调用处的构造函数名,都统一为结构体名
实例:
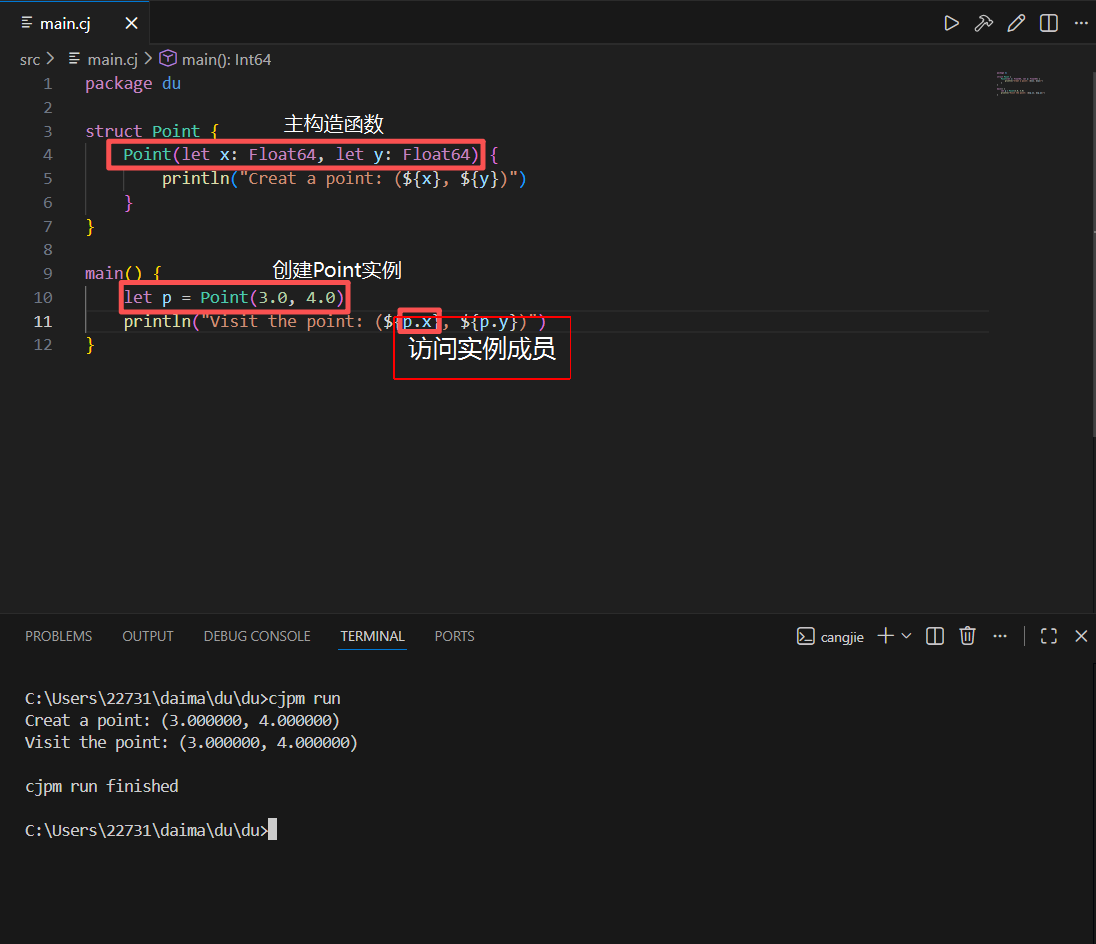
我们定义了一个名为 Point 的结构体,并在主构造函数中,定义了两个成员变量 x 和 y,在 main 函数中调用构造函数,创建了 Point 实例,对应的成员变量 x 和 y 被自动赋值为 3.0 和 4.0,然后我们通过实例 p 去访问这两个成员变量,将它们打印输出
# 成员访问规则
在成员变量、成员函数和成员属性的声明前可以添加一些修饰符,它们将影响成员的访问方式
**private:** 设置成员仅在结构体内可见
**public:** 设置成员仅在结构体内外均可见
如果没有使用这两个修饰符,这类成员默认在当前包内可见
static:设置成员为静态成员,只能通过结构体名访问,没有 static 修饰的成员默认为实例成员,只能由实例变量访问
在实例成员函数中可以引用其他成员,在静态成员函数中只能引用静态成员
在实例成员函数中可以使用 this 变量,它默认为当前实例的拷贝,而且是不可变变量
如果需要在实例成员函数中修饰可变实例成员变量,需要在成员函数前添加 mat 修饰符,其中的 this 就是当前实例的引用,通过这个 this 变量就能修饰当前实例
这些特殊规则主要源于结构体的存储方式
实例:
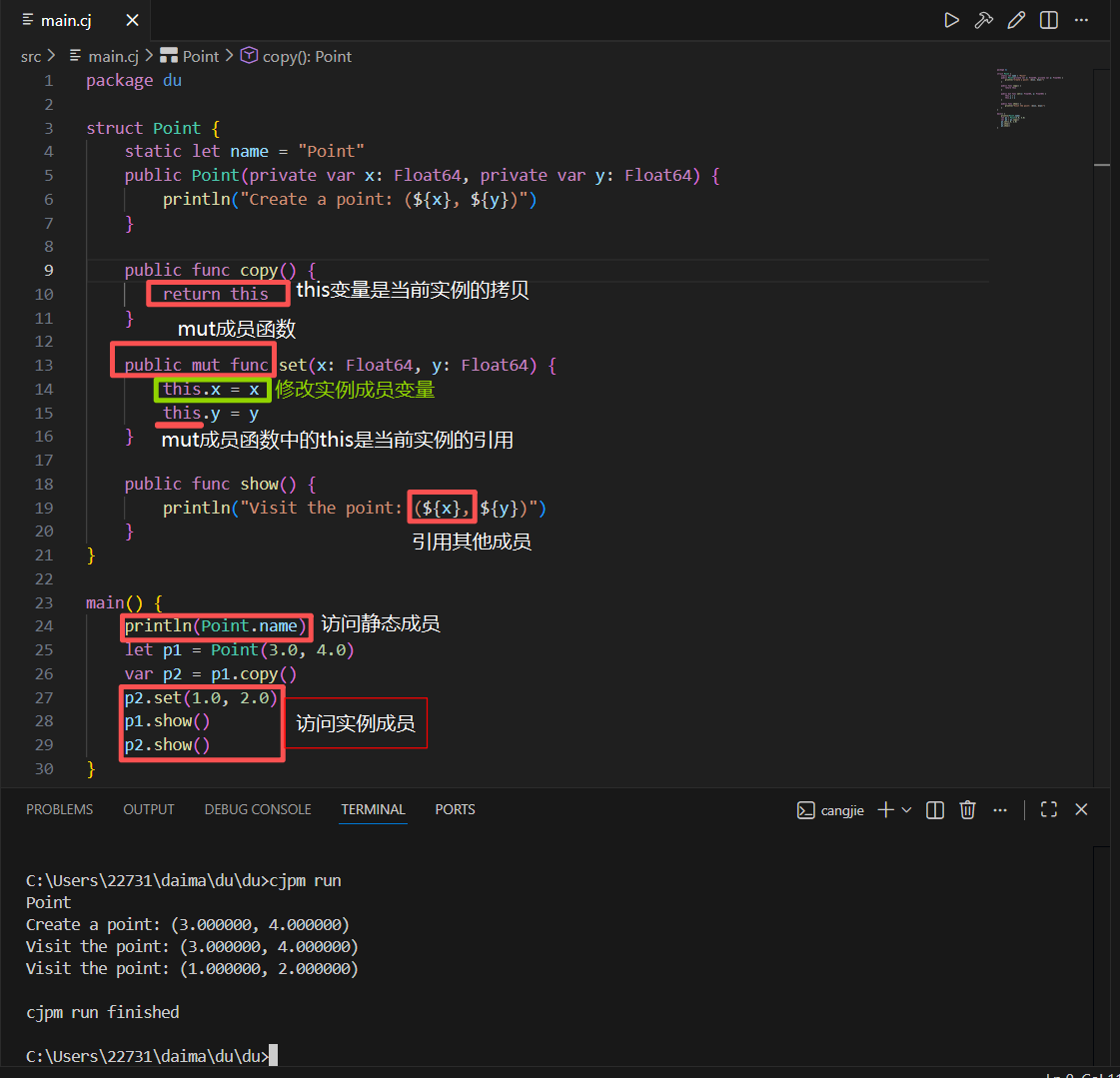
我们定义了静态成员变量 name,并通过结构体名访问和打印了 name 的值,我们还定义了两个 private 修饰的实例成员变量,这样我们就不能在结构体外,通过成员名字访问它们,为了能在外部修改这两个变量,我们定义了 public 和 mut 修饰的实例成员函数 set,因为有 mut 修饰,就只能通过 this 引用当前实例,我们借此为成员 x 和 y 进行赋值
此外,我们定义了 pubilc 修饰的实例成员函数 copy,它直接返回 this,也就是当前结构体实例的拷贝,因此 main 函数中的 p1 和 p2 是两个不同的实例,p2 调用 set 修改成员变量并不影响 p1
# 应用实例
这里我们使用结构体和 Option 类型作另一种实现,结构体 Node 表示二叉树的节点,在主构造函数中,我们定义了三个成员函数变量,value 用于存储节点的值,left 和 right 将存储节点的左右子树,由于左右子树是可选的,因此我们使用了 Option<Node> 类型,在主构造函数的参数列表中,也可以定义命名参数和默认值,这里为 left 和 right 设置了默认值 Node